3. Loss function and optimization
1. SVM loss

L = max (0, 437.9 - (-96.8) + 1) + max(0, 61.95 - (-96.8) + 1) = max(0, 535.7) + max(0, 159.75) = 695.45
大白话说就是非标签的那几个分别都减一下标签的那一个数值,加上1(也是一个超参数,即阈值)之后和0比,取max,最后求和。
目的就是想要保证标签的那个对应的数值要比其他的所有数值都要大至少阈值(此处是1)那么多。
当然,也有L2-SVM,就是每个max之后取个平方再求合。不平方就叫hinge loss,平方了叫squared hinge loss。
2. Softmax loss
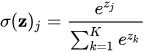
大白话就是标签的那个的exp除以所有的exp之后的和
一般会在外面加个-log,因为softmax之后的值介于0和1之间,加了log之后小于0,所以要加-号。
流程(softmax = exp + normalize):

3. SVM VS Softmax
SVM等到错误的比正确的那个的数值低一个阈值就完事了,然后就不会变了,因为lost已经是0了。但是softmax会尽力让对的数值一直上升到infinite,使得错误的数值一直降低到-infinite。
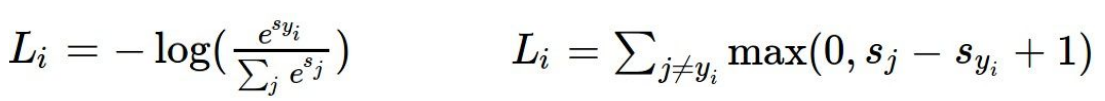
4. Optimization
就是梯度下降:
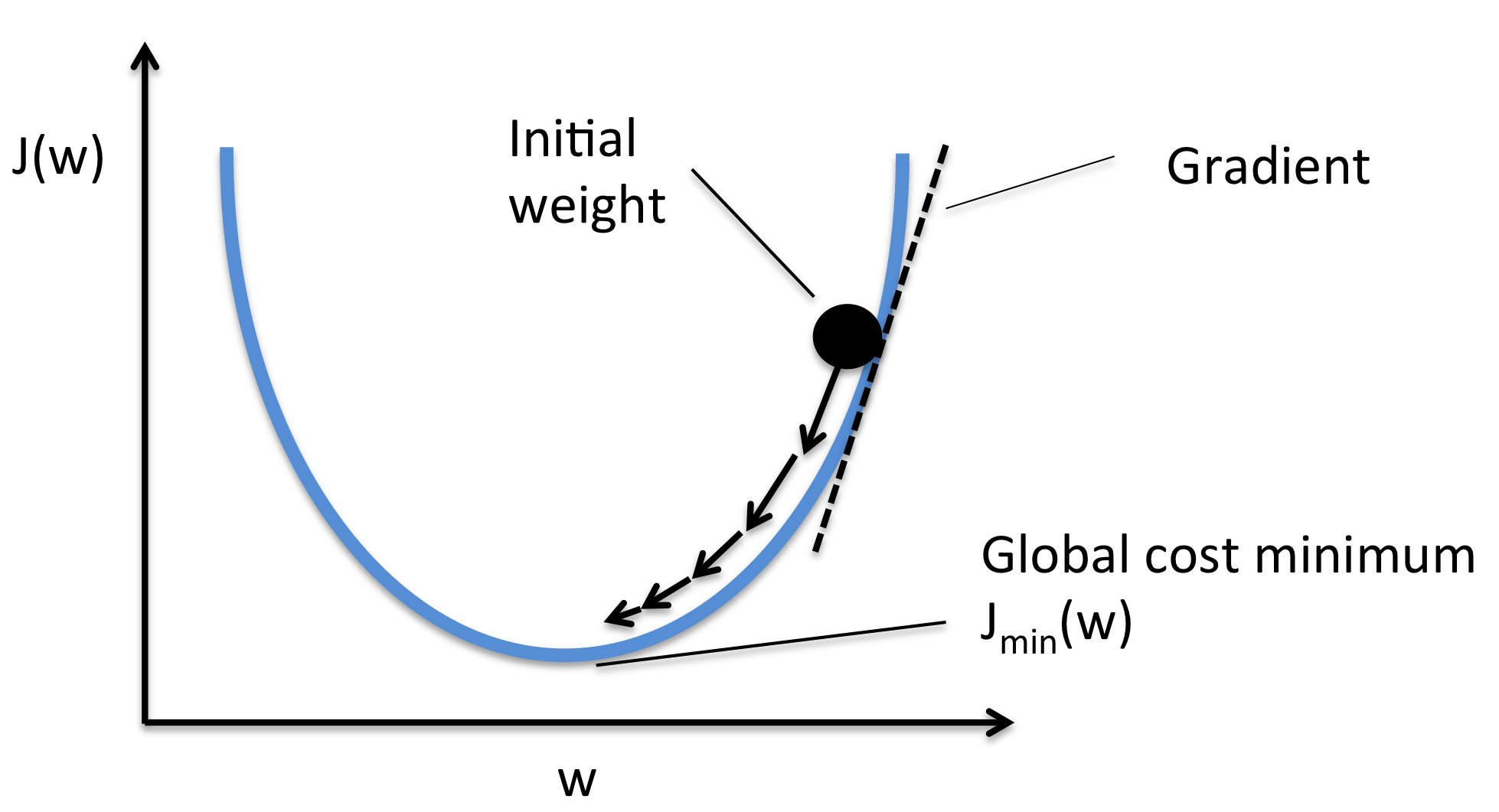
W = W - learning_rate * W_grad
SGD(Stochastic Gradient Descent): 随机梯度下降,就是如果用所有的数据就会非常消耗计算资源 而SGD只是随机的选择其中的一部分
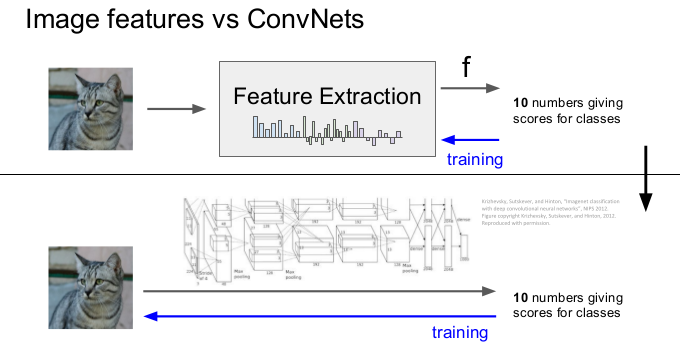
5. 特征工程
在出现dl之前,人们手动标注特征,启发其实就是特征转换,某些复杂的特征经过转换可以直接变成简单的特征,比如下图(直角坐标系向极坐标系的转换):

有两个例子(常用的特征工程的):
5.1 Color Histogram
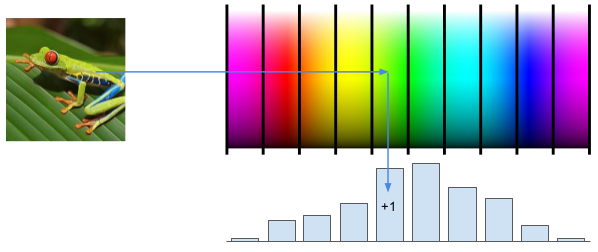
就是一些相近颜色就被标注了相同的值了,这个主要就是针对了颜色这个特征
5.2 Histogram of Oriented Gradients (HoG) (全局特征)

就是8*8的像素区域作为一个bin,每个bin用一个九维向量来代表,而这个九维的向量就是根据梯度来计算的,这个主要针对的是方向这个特征(当物体方向变化太大的时候,HOG就表现的不好了)。
个人观点:其实每个bin就很像dl里面的一个神经节点
5.3 Scale Invariant Feature Transform (SIFT) (局部特征)
SIFT,尺度不变特征转换(Scale-invariant feature transform,SIFT)(也就是即使改变旋转角度,图像亮度或拍摄视角,仍然能够得到好的检测效果。),是用于图像处理领域的一种描述子。这种描述具有尺度不变性,可在图像中检测出关键点。是一种局部描述子。
SIFT和HOG都涉及到DIP的内容,可以参考这俩网站:
https://blog.csdn.net/diligent_321/article/details/84967192
https://yq.aliyun.com/articles/682080
5.4 Bag of Words(BoW)
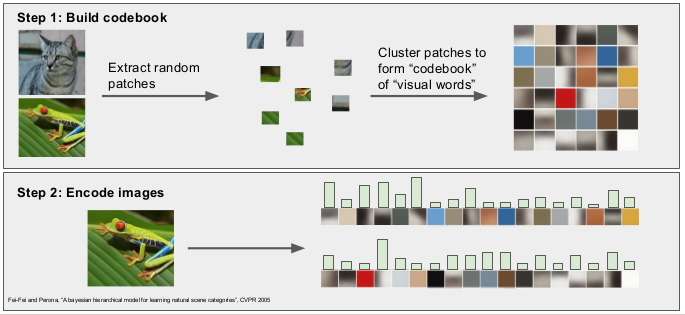
图像特征提取
图像可以类比为文档,图像中的单词可以定义为一个图像块的特征向量。那么图像的BoW模型即是 “图像中所有图像块的特征向量得到的直方图”。
1.特征提取
假设有N张图像,第i张图像图像可由n(i)个image patch组成, 也即可以由n(i)个特征向量表达。则总共能得sum(n(i))个特征向量(即单词)。 特征向量可以使用SIFT方法获取,每一个patch特征向量的维数是128。
2.生成词典/码本
假设词典的大小为100,即有100个词。用K-means算法对所有的patch进行聚类,k=100,当k-means收敛时,我们也得到了每一个聚类最后的质心,那么这100个质心(维数128)就是词典里的100个词了,词典构建完毕。
3.根据码本生成直方图
对每张图片,通过最近邻计算该图片的每个 “单词”应该属于聚类中的“哪一类”单词,从而得到该图片对应于该码本的BoW表示。
Bag-of-words模型构建完成,就可以进行分类、预测等训练
DL出现之后,特征工程的工作就被卷积等网络取代了: