11. Detection and Segmentation
[TOC]
1 CV任务概述
参考该github:
https://github.com/mbadry1/CS231n-2017-Summary#12-visualizing-and-understanding
computer vision 主要有四个任务: 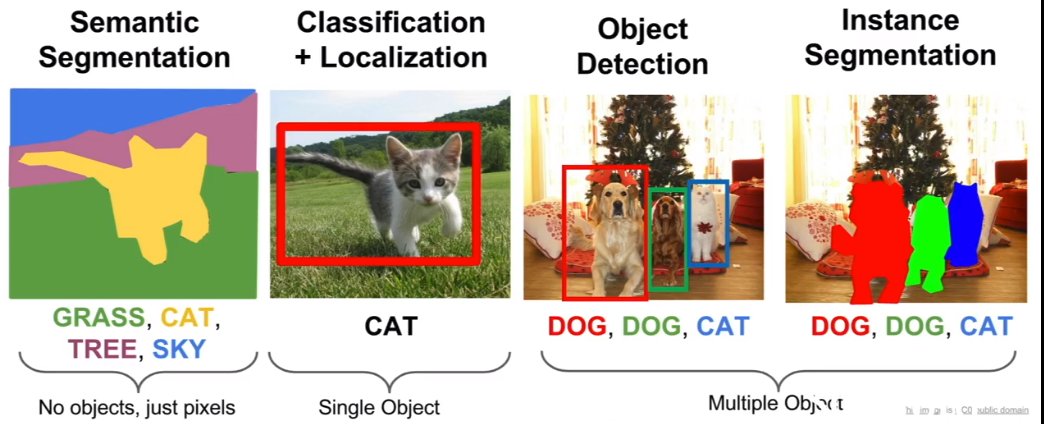
2 semantic segmentation
就是对图片上的所有像素点进行分类,是不区分相同物体的
三个方法:
- sliding window, 但是计算量很大而且不复用
- 端到端的深度神经网络, 但是需要大量的label的图,非常昂贵
- 基于第二个方法,先降采样,再上采样
论文链接: https://arxiv.org/pdf/1603.07285.pdf
3 classification + localization
这个就是预设了图片中只有一个需要检测的目标
然后对这个目标做classification,对这个目标的框的四个定点坐标做regression
Loss = SoftmaxLoss(classification) + L2 loss(regression)
该技术也会在pose estimation里面使用
4. object detection
The core idea of C.V.
这个任务和classification + localization的区别就是你不知道图里面有多少对象
方法:
1. 使用sliding window
分出很多crops,每个crop上面使用CNN。
非常消耗计算量。但是效果好。
2. 使用SS(Selective Search)来寻找Region Proposals
SS方法是基于传统DIP的其实
基于这些Region Proposals,做CNN
一般SS之后会在几秒内(CPU)给出大概一两千的regions。因此比sliding window相对快一些
3. R-CNN
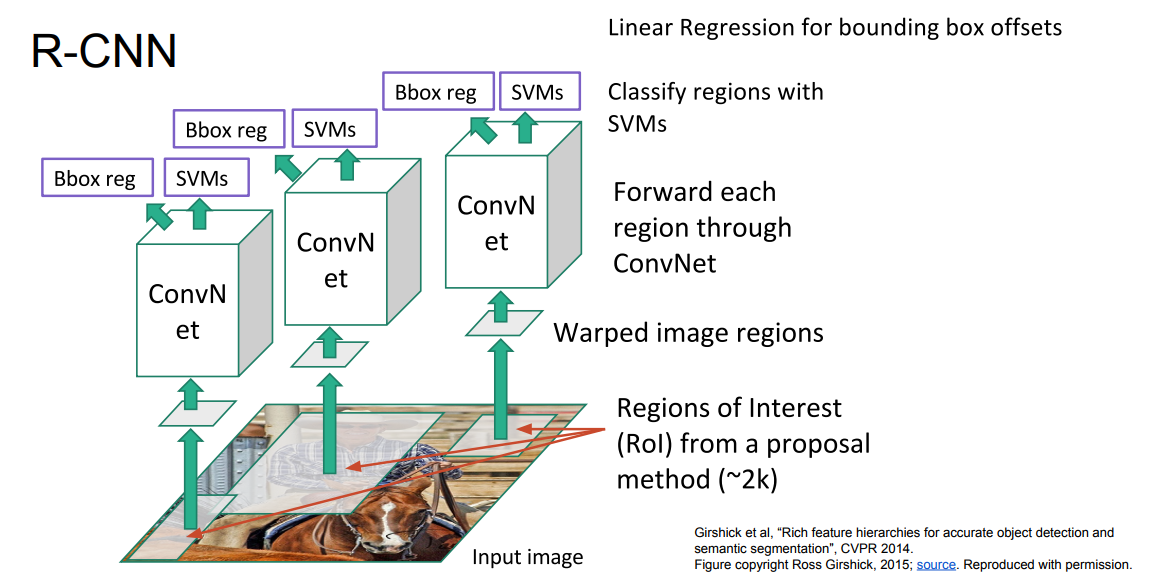
不好,因为要把Roiscale,而scale不好
另外,这个方法也很慢
4. Fast R-CNN
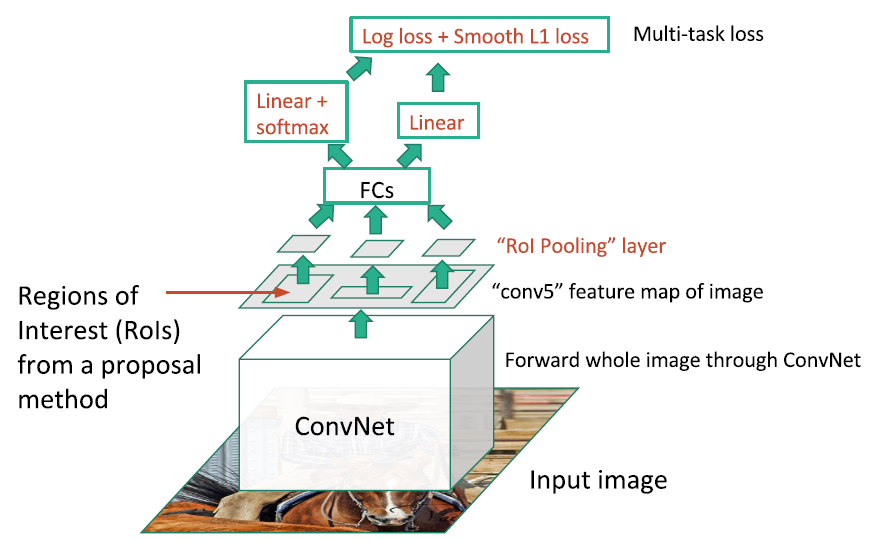
就是先对图做一个cnn,在cnn的某一层再做方法2(SS那些)
5. Faster R-CNN
对Fast R-CNN的改进其实就是在检测框(Region Proposals)的生成那里不再使用SS方法了,而是使用Region Proposal Networks(RPN),这样就快了很多
RPN: 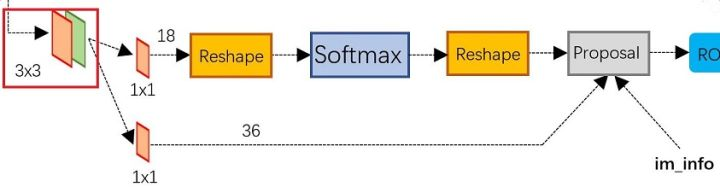
6. YOLO(You Only Look Once)
faster但是不那么accurate
7. 最好的方法总结
- Faster R-CNN is slower but more accurate.
- SSD/YOLO is much faster but not as accurate.
5 Dense Captioning
Object Detection + Captioning 介绍论文链接; http://www.micc.unifi.it/bagdanov/pdfs/densecap.pdf
6 instance segmentation
最复杂的任务,就是前面的合体。semantic segementation + object detection
就是不仅仅要把多个object分类分出来,还要分别进行像素级别的定位与区分(而不是框住就完事了) 有很多方法。
比较新而且好的叫:Mask R-CNN。 这个很像R-CNN,但是我们在里面运用了semantic segementation